Notes App Dev Diary #1
For the first time in months, I remembered what it was like to be obsessive about my work: always trying to get in one more feature before bed and then staying up too late. It's been nice to feel that again after a long break, but even better to be able to see it with fresh eyes and think about it more clearly. I suspect that I'd grown habits around the way I approached my work (both the technical and non-technical aspects of it) that might have been local maxima.
In between interview prep stuff, I've been working on a side-project to empower players in tabletop roleplaying games like D&D to take notes that make campaigns more memorable. Here's a rough pitch:
Since the game world is defined by what happens at the table, good notes should lead to more immersive worlds and memorable stories.
For a start, I'm trying to empower three particular players since my friends and I have struggled to manage our one hundred forty-two page Google Doc where we keep the last three years of notes about our ongoing campaign. The loading time sucks. Searchability is surprisingly bad because no one spells the names of fantasy NPCs (non-player characters) correctly or consistently. Answering questions like "When did we last talk to this person?" or "How many days has it been since we left town?" can take a while to answer, which breaks immersion.
I've talked to these friends for years about wanting to do something about it, and this is me taking a swing at it.
I drafted this dev diary after my first week working on the notes app, and I'm sharing it now just for fun – nothing is ready for folks to play with yet. Here are my miscellaneous learnings from that week.
Flow is fun, decision making is draining.
The best part of the process is when you know exactly what you want and get to chip away at it piece by piece until it's done. Most coding problems get me into that flow state; even though coding requires making a lot of small decisions, it feels like solving a puzzle. Solving simple puzzles are more fun than work. The reward of solving it is greater than the cost of the exertion, and it makes you feel smart. However, making challenging decisions is draining for me to the point where it's demotivating.
I think what differentiates the easy decisions from the hard ones is that easy decisions have a clearer "right" answer, provide feedback sooner, and have better understood costs for correcting them.
For example, implementing a straightforward UI component can be fun because you get quick feedback and an obvious way to iterate. It's almost like sculpting in that you can get the basic shapes in quickly, then iterate until it's right. Slap some <div>'s in there, add some basic CSS, and then take a look. Looks too crowded? Add some white space. Font isn't legible? Make it bigger (or better yet: work on your visual hierarchy). Most of the time, you know what you can do to make it better, and you can do it in small chunks.
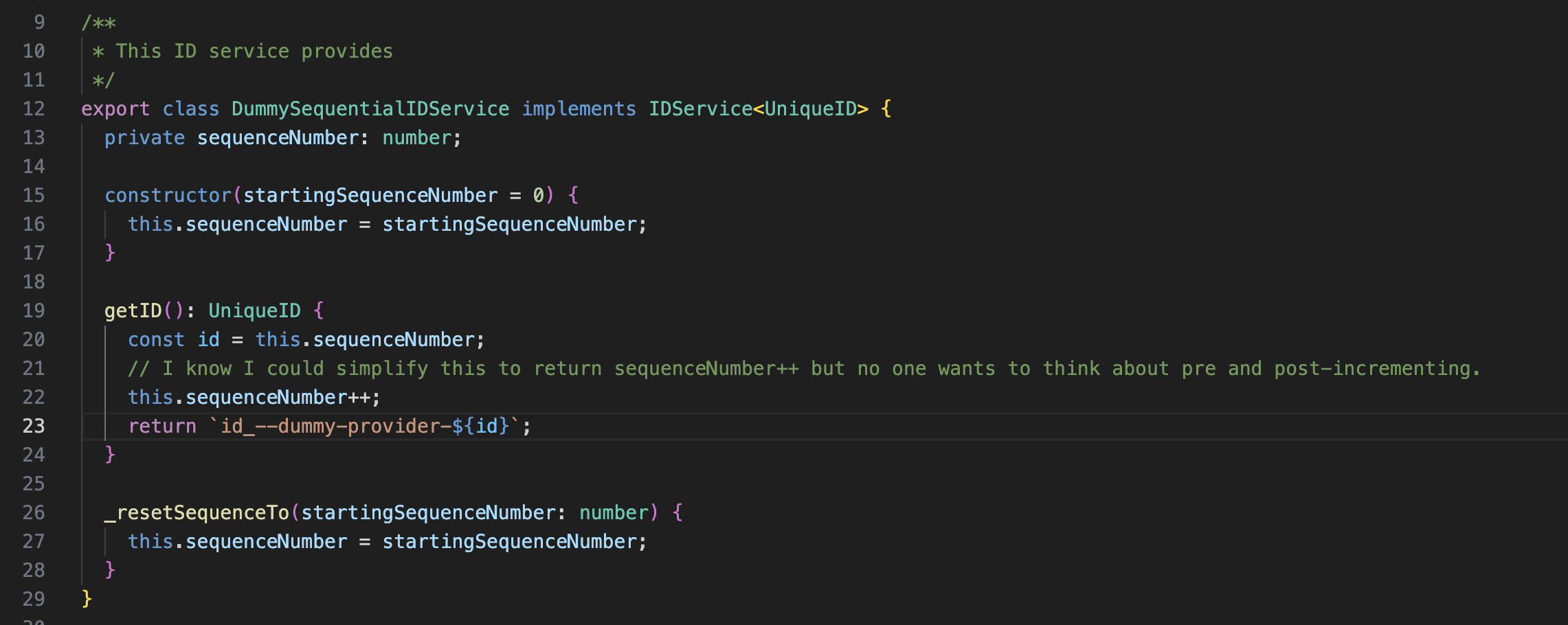
Many technical problems look this way too: Writing a parser? Make it simple then iterate on it until it's better. Need an ID service? Write one that hands out sequential numbers and wait to refactor until you need one that can shard across multiple clients. Need a client-server protocol? Bash out something naive that causes conflicting writes to clobber each other and wait until your product has n > 1 users before you pull out the CRDTs.
🐿️ Aside: CRDT stands for "Conflict-free Replicated Data-Types"
They're a class of data structures that support simultaneous editing like you might see in Google Docs or Figma. (Though Google Docs uses an older algorithm called "Operational Transform"; see the first link for more details.)
Here are some resources:
- Joseph Gentle: CRDTs Are The Future
- Joseph Gentle: CRDTs Go Brrr
- Martin Kleppman (author of Designing Data Intensive Applications) gave a talk: CRDTs the Hard Parts
- Two popular libraries that implement them: yjs and Automerge
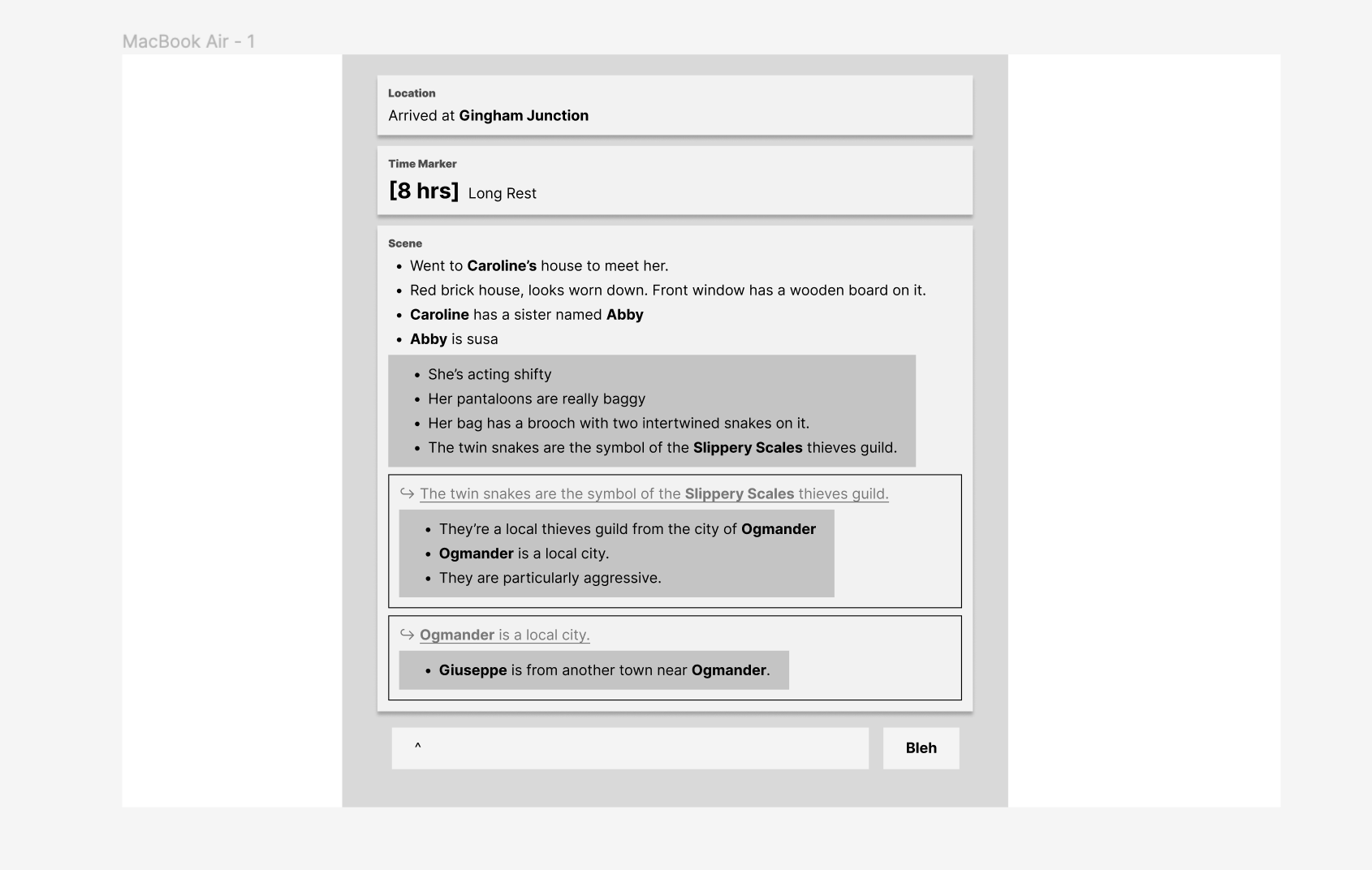
In the case of something harder, the impact of the decision is less well known. During the week, I ran into this a few times when trying to decide which feature to build next. There's no one else on this project that knows the user's needs better than I do for the obvious reason of "I'm the only person working on this project", so when I run out of insight into the next thing to try, I'm stuck. The first time this happened, the prototype was as hacky as it could be: The data model was basically non-existent since I just wanted to fake enough of it to get a feel for the types of journal entries I had built (which were basic text and markers, each of which was a single field that was managed locally with React state). I wanted to test adding a quote callout entry, which would support having two fields: the quote text and an optional attribution line (i.e. who said the quote). Creating that would require either improving my parser or adding some WYSIWYG authoring UI. Adding that UI would require some more refactoring to change my static text components to support editing.

Left: The syntax in the composer for creating a quote entry. Right: An example of how one is rendered in the UI
I ended doing a mix of both: I refactored my UI to support editing, but didn't quite build a full WYSIWYG composer interface.
🐿️ Aside: "Composers"
In Facebook (and I presume other products), the post authoring interface is called the "composer". Even though most of the text fields in my app can also become editable text inputs, that particular one is special because it has to help the user create any kind of journal entry that the app supports.
I'm reminded of Jeff Bezos' system for categorizing decisions into Type 1 (hard to reverse) vs Type 2 (easy to reverse). That framework is helpful for me since it removes the pressure of having to optimize every single decision, but even still, it's hard to know whether a decision is Type 1 or Type 2 when any decision I make requires committing hours of time to coding it up, and I might not know whether it's part of a "magic moment" until it's had days or weeks of testing.
Thinking "better" is more efficient than thinking "harder".
When I get really wrapped up in a task, I feel compelled to not stop. This gets annoying when it would be more efficient to call it a day and drop the problem from my brain instead of stewing on it. This gets especially unhelpful when it coincides with having to make a decision through some uncertainty. My desire to make progress on the problem every waking moment (or at least to keep the problem fresh in my mind so that I don't lose context) leads me to think about whatever I'm stuck on 24/7. In the shower. While taking a walk. While pretending to pay attention to a YouTube video. Always. I remember there were times as a new grad where people would walk up to me and ask me a question and I'd totally miss that they'd said something because I was still stuck in my head and hadn't taken a step back to "be a human again".
I remember that when I'd have to make these sorts of tough decisions, my brain would fog up, the way that it does when I'm shoved in front of a whiteboard coding problem after not having done one for too long. It's not that I can't solve it, but until I get over the mental block, it's slow going. I'm starting to think that this is more of a learned reaction to these sorts of problems rather than an inherent part of how I think, and maybe the culprit is trying to keep the whole problem in my head instead of using other thinking aids like writing a document or drawing a diagram.
For example, I needed to figure out what feature to build next based on how much it would inform my product hypotheses. There wasn't an obvious answer, and it was clear that whatever I tried, it would take a while to validate. I found myself impulsively turning over all the possibilities in my head: maybe option A could be justified because of this, or maybe option B ought to supersede it because of some other principle. Eventually I had to tell myself to stop thinking about it because I was draining my mental "juice" running the same thoughts over and over again in my head like a mercury delay line: spinning and repeating in an attempt to prevent the thought from decaying, but without the focused thinking needed to distill it and make forward progress.
I brainstormed some ideas for how to spot and break these cycles:
- Identify when I can't make any more forward progress, and put the problem down for a bit. It might be clearer in the morning, or some inspiration might strike from another place.
- Write things down instead of trying to keep it in my head. Don't waste valuable brain juice on keeping things remembered. Make it OK to stop thinking about the problem because you've committed it to a place where you can easily get caught back up. (And who knows, maybe the act of writing will lead to clarity.)
- Pay attention to my body and do the things I know I need to do to take care of myself, even when I don't feel like doing them because I'm hyperfocused on a problem. Basic things like "If I eat something, my brain will clear up and I'll not feel like I have to finish every single thing right now."
- Try to unload my brain before I go to bed. I enjoy falling asleep while chewing on a problem. That's probably unhealthy, but it usually works if what I'm turning over is unimportant and I can let it fade into nonsense as I fall asleep. But it really doesn't work when I'm still wound up and invested in solving the problem because instead of helping me let go and fall asleep, it keeps me wound up and anxious.
Iterative development means continuous refactoring and migration.

I never really connected the dots that iterative development necessarily implies having to refactor things constantly. I associated refactoring with bigger code bases, not greenfield solo projects, but I found myself constantly refactoring every time I implemented another set of features. In retrospect it's pretty clear why: when prototyping, you don't know what your final goal state is, so you can't make big architectural decisions that account for everything you'll need. With the exploratory prototyping I was doing, I didn't have a clearly defined product with specs or a PRD, or even a comprehensive mock in Figma. The only sane way to implement features without overthinking them was to implement them in the barest, hackiest way possible. Just trying to make something I could poke at to vibe it out and try to find where the magic moments are. So naturally, every time I needed to build a new feature, I'd have to refactor out the placeholders and hacks that were there before.
Refactoring by itself isn't an issue. It's a normal part of all software engineering work. The more challenging part is managing migrations and consistency. This, again, is something that I had only associated with big systems. So many of my and my friends' projects at work over the years have been migration related. Migrations are hard, and maintaining backwards compatibility until you're ready to cut over requires a lot of planning. Because I was refactoring the data model so much as I added new journal entry types, I started running into compatibility and migration issues even though I was only three days into developing this project.
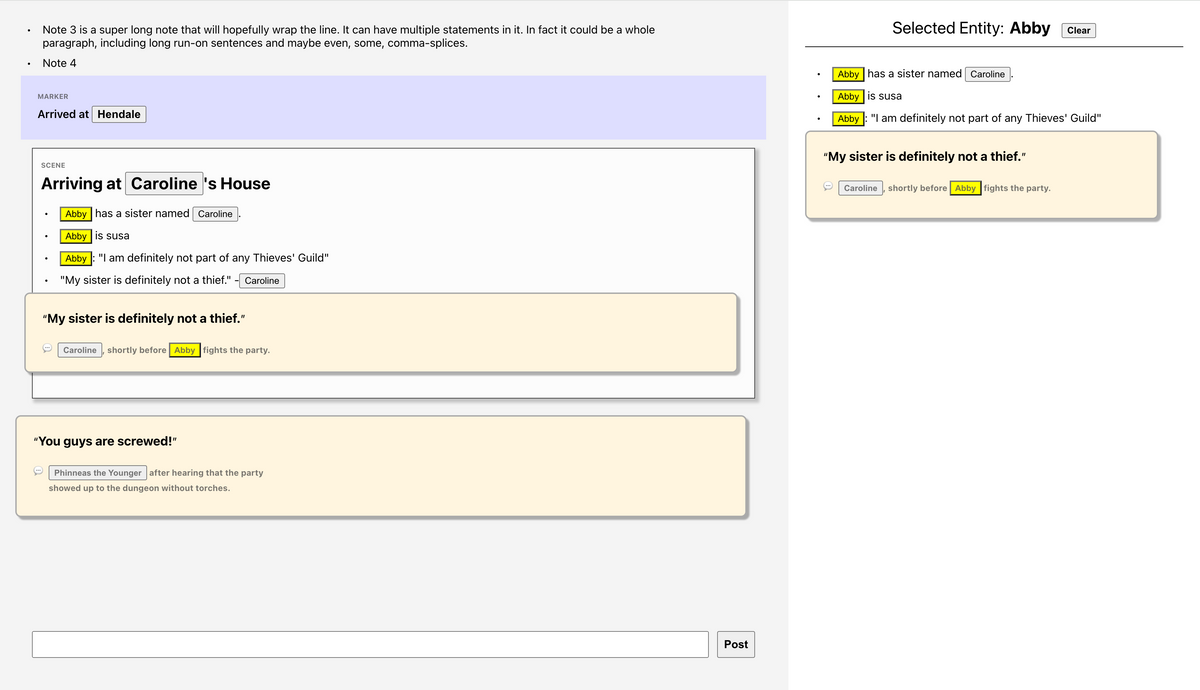
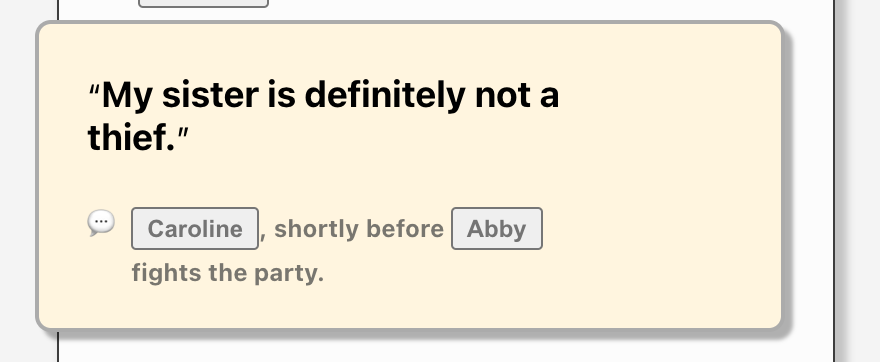
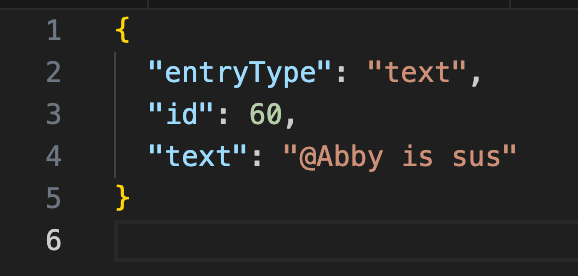
Some changes were simple to account for: I added the ability to add titles to scenes, so I added a new title field and made it optional. Easy. All the previous samples kept passing typechecking and rendered just fine. Then I refactored the way text with entities is parsed (i.e. turning "@Abby is sus" into "Abby is sus").


Text with a tagged entity on the left, and how it's rendered, on the right.
Originally, I parsed it when it was rendered with a couple optimizations to make it acceptably performant for the prototype: a custom tokenizer to parse it in a single pass and some memoization. But when I wanted to implement a tag search feature, I thought it would be more efficient to parse the text when it was added to the journal and store the parsed entities with each entry. This meant that all my previous example data (both real data from testing and sample data) needed to be migrated to use the new types, which was daunting because almost every field that used to be a string was now an object with multiple properties that required parsing to accurately spit out.
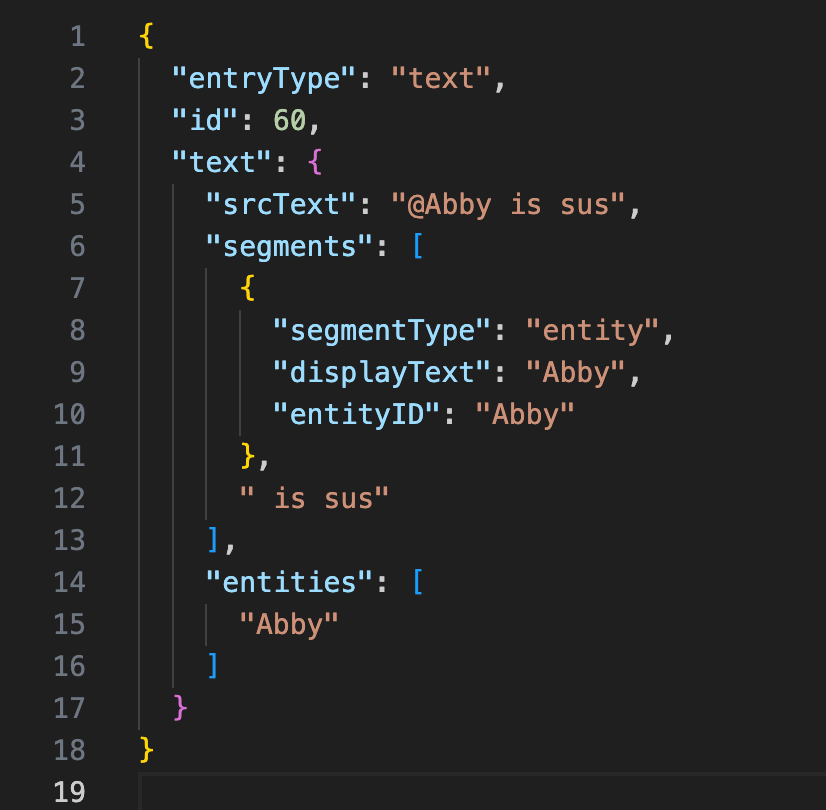
Left: The simple JSON structure before the refactor. Right: The more complex structure post-refactor.
On its own, this would be a trivial refactor, and all future text entries would be created in the new format without issue. However, I had tested out the app for one real session of D&D with my friends and now I had a whole session's worth of notes that I had to migrate to the new format. It was frustrating to deal with maintaining this "real" test data while iterating, but in the end I think it's worth it. Testing is the only way to really learn what's working, so I think this is going to force me to build better tools for managing these data migrations.
The new Typescript definitions didn't match the signatures of the data created with the old format, so not only would it not render, but the app wouldn't even build because the old data failed to type check. I ended up using a mix of regex and migration functions to make it work: regex to replace the plain strings with dummy objects that contained the raw strings but not the parsed entities (thus matching the type definitions but being semantically incorrect), and then a migration function that took in those dummy objects and re-parsed every string to get the data to be consistent.
VS Code's regex find and replace (⌘+F, then click the .* in the search menu) has been a useful hammer for me many times in the past. In this case, I took my JSON file and ran this regex over it:
Find: "text": "(.*)"\n
Replace: "text": {"srcText":"$1","segments":[],"entities": []}\nThis matches JSON entries with key "text" and a quoted value, then captures the part in quotes using (.*) and finally replaces it with a JSON object that has the property "srcText" set to the captured value using $1. The rest of the object has the correct types (empty arrays), but doesn't contain real data yet.
With this kludge in place, the .json file passed type checking and I could use code to continue the migration. I just needed to run the text parser on text.srcText and substitute in that result instead.

Testing is the only way to know where you stand.
Actually committing ideas into a prototype and then testing it is how dreams die. But it's also how great products are born. You can't solve the whole problem on paper without testing it out, so the only way to really focus on your problem is to not be in love with your solution. And the way you do that is by dashing your solution against the rocks as fast as possible. This is all pretty well-accepted dogma at this point, but it still hurts to do.
I was sure that my scene-based note taking would be the foundation for better D&D notes, but then I tried it out for one session and realized that when you try to take notes on a scene, half the time you're just transcribing the scene. Sure the app can give you more structure, but it's not encouraging you to take efficient notes, and all the energy and attention you're putting into the app is a direct tradeoff against being present at the table with your friends. Furthermore, it turns out that for the game I'm currently playing in, the story doesn't tend to play out in clean "scenes" that all happen at one place and time so much as it does in "sequences", or strings of events, attempts, and often short scenes that are all tied together by a common goal or story beat. So that's all gonna need some tweaking.
Similarly, I was confident that using tagged entities in the notes would lead to a much better way to organize knowledge: essentially turning your session notes into wiki articles about all the things in your world. I tried prototyping the "wiki" pages as a tag search. It turns out: when you search for the player characters, you get almost every entry in the journal because the PCs are in every scene. Not very helpful. When you search for more obscure things, it can be a bit more helpful, but it's still a lot of barely-structured text to sift through. That was a rude awakening because I was counting on this tagging and auto-organizing feature being a differentiator over a generic text editors like Google Docs or Notion. I'm glad I got this learning early: it's not enough to just dig up relevant notes, the real value-add is separating important notes from unimportant ones. I've got to start figuring out what players are looking for when they look at their notes or a wiki in the first place. Maybe it's to remember where they met a person, or to confirm if they'd ever heard a certain name before. Or maybe it's to recall the description of a city they'd been to before, to keep the world feeling real and show the DM they're invested. In those cases, it's important to separate out important info like "The city of Mithralhelm is a Dwarven city known for crafting items out of mithral." from un-interesting mentions like "Got to gates of Mithralhelm".
Have a hypothesis for what delivers value and focus on that to make decisions.
Two of the features I thought would be slam-dunk cornerstones of the experience turned out to need lots of tweaking: grouping notes into scenes wasn't as good a match for how things play out at the table as I thought, and organizing notes by tagging entities wasn't an automatic win like I had naively hoped. That said, I feel like these learnings pushed me further towards understanding why the things that work will actually work: taking more notes is not better. It's far better to be efficient at taking the most useful notes instead.
I hypothesize that there are three main ways that notes can make the game better:
- They improve verisimilitude by recording time and place more accurately, so that the world can develop in response to what the players do.
- They help players remember key bits of lore and clues that allow them to figure out important mysteries about the world or plot.
- They help players remember the most dramatic, emotional, and interesting things that happened so that they can revisit or retell it later.
So while I'm still a bit sad that my first swing wasn't a home run, I think my learnings ultimately support my hypothesis. There are clearly better and worse ways to take notes, which means that there's a place for a product that nudges you towards better note taking. For my next iteration, I'll have to make sure I don't conflate "more notes" with "better notes", and learn what truly effective notes look like in practice (e.g. what new kinds of journal entries to build or how to organize the types I already have).
Technical PS: Making React components more efficient with memo(...)
I've worked with React for years now, but I just learned this week that React will re-render all child components when its parent re-renders unless you wrap that component with React.memo(...). This signals to React that your component is actually a pure function like it's supposed to be, and will not re-render your component if its props don't change. I thought this was the whole point of React, to limit the amount of re-rendering done by scoping down state updates when props don't change, but I guess it's not automatic. I've always written React components to minimize un-necessary re-rendering with thrashy state changes, or subtle reference changes (e.g. recreating arrays or objects using spreading when they haven't changed), or lists without keys, but I didn't realize I had to use React.memo too.
I found it by using the profiler. This isn't the first time I've prototyped a text editing experience, so I knew going into this that typing needed to feel smooth for the UX to be acceptable. After looking at the profiler results on a small data set with fewer than 20 journal entries, I tried it on a larger one with hundreds of entries to see if render times for each keystroke were scaling with the number of entries. Turns out, yes. Each entry only took a fraction of a millisecond to render, but with hundreds of them, that added up to 10+ms for a state update on every keystroke. Totally unacceptable. After adding in memoization, I saw most entries not re-render on each keystroke, taking the state update time down to <1ms. More importantly, it no longer scales with the number of journal entries (at least not significantly – technically the underlying data model manipulation does require O(n) scans of the journal's underlying data to update. This too can be easily fixed in a future refactor.)